

An in depth view of current technology and strategies used to create redundancy in your WAN and how to properly design, implement, monitor and test in case of any disaster that may occur as well as covering briefly other redundancy options.
Introduction
Now more than ever, today’s businesses require reliable network connectivity and access to corporate resources. Connections to and from business units, vendors and SOHOs are all equally important to keep the continuity when needed. Business runs all day, every day and even in off hours. Most companies run operations around the clock, seven days a week so it’s important to realize that to keep a solid business continuity strategy, redundancy technologies should be considered and/or implemented.
So, we need to keep things up and available all the time. This is sometimes referred to five nines (99.999) uptime. The small percentage of downtime is accounted for unforeseen incidents, or ‘scheduled maintenance’ and usually set to take place during times of least impact, like in the middle of the night, or on holiday weekends if planned. If this is not a part of your systems and network architecture it should be considered if you want to keep a high level of availability. Because things break and unforeseen events do take place, we need to evaluate the need for creating an architecture that is ‘highly available’, or up as much as possible, with failures foreseen ahead of time and the only downtime, is to do planned maintenance.
To keep the company’s workforces, and their customers connected and operating, we need to plan for it. With servers you can cluster and with web properties and applications, you can load balance. Almost every vendor today puts out a line of products to facilitate this need via hardware, software and now via virtualization design.
In this article we will take an in depth view of current technology and strategies used to create redundancy in your WAN and how to properly design, implement, monitor and test in case of any disaster that may occur. We will also briefly cover other redundancy options for servers and other network architecture, power and applications.
The Importance of Redundancy
Today’s networks are high-tech and most times high speed. Common to most Wide Area Network (WAN) designs is the need for a backup to take over in case of any type of failure to your main link. A simple scenario would be if you had a single T1 connection from your core site to each remote office or branch office you connect with. What if that link went down? How would you continue your operations if it did? In this section we will explore this scenario and other scenarios to help you design and plan for a backup solution that you can count on and one that is cost effective and will not break the bank.
Network redundancy is a simple concept to understand. If you have a single point of failure and it fails you, then you have nothing to rely on. If you put in a secondary (or tertiary) method of access, then when the main connection goes down, you will have a way to connect to resources and keep the business operational.
The first step in creating network redundancy (particularly in the WAN), is to set up a project plan that will allow you to scrutinize the current architecture/infrastructure, plan for a way to make it redundant, plan for a way to deploy it and then set up a way to test it. Nothing should be thought of as ‘complete’ until you have tested everything for operational success. Your final step will be putting in policy and processes that allow you to monitor it and be alerted when things do fail so you can take action. Commonly a company’s security policy, disaster recovery plan, business continuity plan and/or incident response plan will leave room for this type of solution.
Testing however is the key to your success. This is not a ‘set it and forget it’ design. The main link failing means that the backup should take over automatically if that is how you designed it. There can be one of multiple issues that may not be self-repairable, or resolvable without interaction so if not set automatically, you will need an incident response plan to account for it. You should also have a follow-up procedure regardless of automatic or manual. This means, when implementing redundancy into your systems or network, you need to take action immediately regardless, even if your operations continue to take place to verify that everything did go as planned. If not, then you need an after-action report where you can specify how things will be fixed, or redesigned – then retested.
Analysis is critical to building a good redundancy plan. Almost every network created is unique in some way. This is why you must analyze and take note of not only the common items that would require redundancy, but also other solutions in place that you may not have considered such as mainframe access as an example.
First, a risk analysis assessment must take place. Next, the core site (or core sites) must be taken into consideration if that is where the bulk of your resources are located, or where the majority of your business connections terminate. Routing and routing protocols need to be considered. Solutions exist (such as when using Cisco Systems devices and software) where specific protocols can be used to handle the failover process for you if implemented correctly. Load balancers, failover solutions and protocols are available to facilitate just about any redundancy option you can imagine.
Note:
You should always consider the hardware. For servers and network devices, redundant hot-swappable power supplies and drives (as well as other components) are used to keep everything up and running when a disaster occurs. Also, disk drives can be deployed in a way where the data is spread across multiple drives such as when using RAID, so that if a drive does fail, the data is not lost. Data should also be saved (backed up) in multiple locations to provide restore redundancy options. Having off-site tape storage is one such example, as well as to have data replicated across multiple hosts using technologies such as Windows DFS.
Tip:
The Local Area Network (LAN) must be examined for single points of failure as well. If your LAN only uses one switch and both routers are connected to it, if the switch fails, so does the LAN, as well as access to the WAN.
Once the design phase is complete, a cost analysis session must be completed as well. Competing business rivals looking for your business will hope that you budget, plan and design this solution incorrectly. Creating redundancy is 90% of the design only leaves you with a possible 10% failure scenario. This means that you spent a lot of time, money and resources putting a solution in place that still has a single point of failure and if this single point creates a significant amount of downtime, then you spent all that time and energy leaving yourself vulnerable to failure regardless. A good management team will ensure that nothing is left open so that the investment is sound and does what it says it will – keep your operations running.
Considering your current network design and architecture is critical (as mentioned earlier). A simplified view of a company network may be a core site location (perhaps the company headquarters) where all of the servers, systems, applications and main infrastructure reside. In this article we will call this ‘core infrastructure’.
Figure 1 shows the layout of an extremely common design, where a branch office needs to connect to a core site where centralized resources are located such as financial applications, enterprise resource planning (ERP) software, databases, file server data and so on.
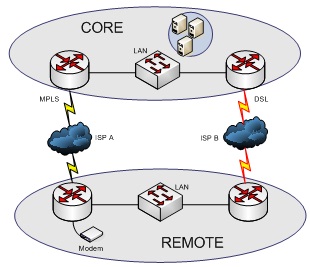
Figure 1: A common WAN connection scenario with redundancy in place
Here you can see how the remote branch office connects to the core site. Here, there is a dedicated MPLS circuit/link that provides bandwidth at approximately 1.5 Mbps which is the connection speed of a T1. The MPLS routers are connected to the network via a network switch. Commonly, the router is the networks default gateway, where all packets are sent that are not found locally. The router needs to make a routing decision and since the main link is up, decides to send via the MPLS connection. When the main link drops, commonly the alternate link is used if set up correctly. This provides your remote site with a new path to reach the resources needed to continue operations.
Back about 10-15 years ago, the technology that connected most corporate sites were Frame Relay and Integrated Services Digital Network (ISDN). Although ISDN is still used in some fashion, Frame Relay has gone by the wayside being replaced by Layer 3 enabled TCP/IP-based high speed networks such as MPLS which we will cover momentarily. The company core and remote sites are normally connected via some form of WAN-based technology, such as OC3’s, T3’s, T1’s, DSL, MPLS and many others. The most common forms today are Multiprotocol Label Switching, or MPLS (private) and some form of Internet connected link (public, or shared) connected via an encrypted tunnel called a Virtual Private Network (VPN).
VPN’s are similar to those you may connect with via your laptop when connecting to work from home. The same technology is used. Since you are connecting over the unprotected public Internet, encryption must be used to secure the transmission of data and communication. Routers and firewalls if ordered with specific VPN functionality installed and enabled can connect your remote sites to a core site in the same manner, encrypting the data you send over the public Internet via what is called a ‘tunnel’. This is often used because it’s cheaper than a managed, dedicated and private MPLS connection and normally lays dormant until used. It’s also secure. Since a SLA is purchased on the main link, the provider needs to get this back up and running quickly so you won’t need to be dependent on the alternate link for long.
MPLS by nature is a redundant network. It is commonly managed by an ISP that provides you a connection to it, or a router that they will manage as well. When data is sent from one site to another, it’s passed into a ‘cloud’ which is a private network that the ISP manages. Packets enter the cloud and into the ISP’s meshed network where redundancy is in place. Although highly available internally, if the router that connects your remote site fails, or the link fails… your site will be down regardless unless you have a redundant router and link there to pick up in the failed routers place.
ISP’s will sometimes offer Internet access via their MPLS network as well. It is not recommended that you use this particular Internet access to connect your VPN tunnels for backup, because it could be potentially connecting to the same network that failed you in the first place.
So, all that remains to answer is one last question – what if both links drop? You should make sure that you have a way into your remote sites via Out of Band (OOB) management, such as a modem connection to a serial port of a connecting router. This gives the chance to test internally to the site (from the local area network [LAN] in times of complete cut off. The modem can be connected to a serial port on a router, or on a server on the LAN. As long as a dial-up line is configured and you can dial into it and connect, you can access your Be sure to secure everything correctly, do not allow someone to war-dial into your network via the modem, which is fairly easy to do if not locked down.
Tip:
You should always create an alternate link in to your remote sites when both links are down. This can be done with an extremely cost-effective (cheap) dial up solution via a POTS line. You can connect a modem to the router, a server or laptop and have LAN access to troubleshoot or provide access out if needed.
There are companies that are more complex, for example if a company’s strategy is to merge and acquire other companies, there may be core infrastructure located in multiple core networks with mission-critical resources. These companies should consider a strategy to simplify the layout and consolidate and relocate to a centralized (and protected) location, but this may not always be the case. In these situations, achieving a redundant network backup plan can be difficult. Sometimes it’s set up like that by design, for example, if you had a core/central headquarters site where some of your resources are located, and others placed in a co-located data center. Using resources outside your network and managed by others (or outsourced) is considered ‘cloud computing’ and SaaS, or ‘software as a service’. Also, you need to consider the differences of keeping services in house or using outsourcing solutions. If your architecture is outsourced partially or completely – you must thoroughly examine the provider’s policy, Service Level Agreement (SLA) and polices for conducting work.
You should also always consider the LAN connections of your routers and the LAN’s default gateway assignment. For better design, create a bullet-proof (redundant) LAN by installing two switches and making them the default gateway. This way, if the router fails completely (such as looses power), the default gateway address is still intact, and the switch can make the decision, not the router. See figure 2 for a redundant LAN connection where routers are connected and the switches make the routing decisions in the case where the router with the default gateway assignment is at risk.
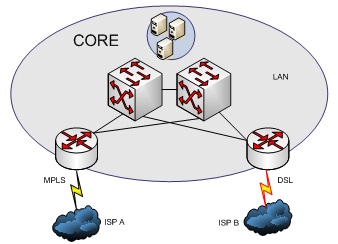
Figure 2: Creating redundancy in your LAN using Multiple Switches
Tip:
It is recommended that you purchase hardware with multiple hot-swappable redundant power supplies, and make sure that the power source is on a generator, has a backup, and/or is phase correctly so you can survive a power lose entirely. Enterprise UPS systems, backup generators and so on can be used to provide alternate and redundant power solutions when needed.
Note:
Ordering lines from an ISP or vendor can take some time so make sure you size them correctly and then order them ahead of time which can save you time with the deployment of your redundancy solution.
Geographical considerations should also be considered. Consider the Point of Presence (POP). If you use one provider and they have internal problems on their network, or a disaster occurs (such as a hurricane) that affects the area, then you will be at the mercy of the provider no matter how many lines you have in place. Disaster recovery solutions account for this, especially if you are using a co-located data center, such as a cold/warm or hot site.
In sum, a simple rule of thumb when designing and planning for redundancy is, do the job right… do not cut corners to save money because if you start to spend capital on redundancy and still leave a single point of failure in place (like a single switch), a small cost could jeopardize the entire solution which did in fact cost you a lot to implement. Lines, routers, human resources to implement it and daily monitoring cost money. It would be silly to leave a simple single point of failure in place when you spent time and money on the rest of the project. Consider doing the project correctly by designing it, budgeting for it and getting the right people in place (or trained) to deploy, manage and monitor it correctly… and lastly, test it for accuracy. Consider everything and leave no stone unturned.
After you have designed and planned your solution, you need to consider a few things during deployment. If in-house solutions are used, your employees need to know how to handle an incident. If out-sourced, then your vendor/provider needs to have a plan in place to add, manage, monitor and then recover from a disaster. Test plans should also be considered in both scenarios.
You should also consider a more complex design when considering how to add and deploy your solution. Figure 3 shows a more common solution for a large company.
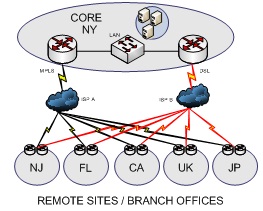
Figure 3: Connecting Multiple Remote Sites to a Core with a Redundant Solution
Here you have multiple remote sites connecting to a core (or multiple core) locations. Redundant links provide an alternate solution to main link failure on your WAN and pro vide remote site access to core resources.
You should also consider failover technologies. Must like server clustering, network equipment can also failover to other devices (such as routers, switches, firewalls, etc.) if configured to do so. For example, a Cisco router can be configured with Hot Standby Router Protocol (HSRP). Servers can be clustered and load balanced for any failover scenario you can think of. With Windows Hyper-V, VMware and Citrix virtualization solutions, you can create a design where any failure can be dealt with automatically keeping operations running in the case of any disaster.
Tip:
It’s important for VPN clients to be able to access corporate resources as well, whether on the road or in a home-based office. That being said, you should consider reviewing your VPN concentrator redundancy as well. If you need two core based units for this strategy, make sure that they also know how to fail over from one to the other in time of need.
Once you have considered your design after full analysis and implemented it, you need to test it thoroughly and then document the procedures. After that, you need to continue to test and update the documentation especially as new technologies are added to your architecture, or as your architecture grows such as adding new sites.
Now that we have talked about the importance of redundancy, especially in the network… you need to test it.
Test Plan – put together a plan that covers the details of a failover scenario so you can test for it. To do this, detail all of the architecture to be tested and failover manually to see how the solution works. Make sure you test applications, routing paths, time/speed/bandwidth usage and accuracy. Test for fail-back as well and how the main link when it becomes available can resume the role of the primary link.
Network Monitoring – your network monitoring solution should help you become aware of a main link failure. Using technologies such as ICMP and SNMP, you can continuously monitor your uptime and be alerted when there is a change in any device, link or solution.
Disaster Recovery Plan – a plan should in place, and if not, added immediately. This plan should outline the
Business Continuity Planning and Incident Response Planning are part of this DR plan. How the business will continue to operate, as well as who will react to the problem and follow it through until normal operations are restored.
Summary
In this article, we looked at adding redundancy into your network. To keep the company’s workforces, and their customers connected and operating, we need to plan for it. With servers you can cluster and with web properties and applications, you can load balance. Network gear can be made highly available. Almost every vendor today puts out a line of products to facilitate this need via hardware, software and now via virtualization design. In this article we took take an in depth view of current technology and strategies used to create redundancy in your WAN and how to properly design, implement, monitor and test in case of any disaster that may occur.
Got a project that needs expert IT support?
From Linux and Microsoft Server to VMware, networking, and more, our team at CR Tech is here to help.
Get personalized support today and ensure your systems are running at peak performance or make sure that your project turns out to be a successful one!
CONTACT US NOW